打开文本图片集
摘 要:本文针对网络学习行为和数据挖掘技术的特点,在适用性学习系统的基础上加入了数据挖掘处理和个性化推荐模块,提出了基于数据挖掘的个性化学习系统模型。重点讨论了个性化推荐模块和基于数据挖掘个性化学习系统的数据挖掘模块的处理过程。
关键词:数据挖掘;个性化学习系统;Web日志
中图分类号:G434文献标识码:B文章编号:1673-8454(2010)11-0085-03
一、引言
为了更好地了解学习者的学习习惯、兴趣和偏好;改善教学网站拓扑结构;提高系统效率;为学习者提供个性化的学习环境,本文结合网络学习系统和数据挖掘的基本理论,构建了基于数据挖掘的个性化学习系统模式和个性化推荐模块。通过数据挖掘分析学习者的个性学习特征和学习需求,通过个性化推荐模块更好地为学习者提供个性化学习。
二、基于数据挖掘的个性化学习系统
1.传统的个性化学习系统
为了提供个性化的学习,近年来人们不断进行着探索与研究。比较有代表性的是具有自适应性的学习研究。[1]适应性学习系统的研究就是按照学习者的知识水平和认知能力提供的个性化学习。如何使自主学习平台具有个性化,笔者通过学习者的预先测试得分、历史成绩、课堂进步来确定学习者的学习进度。适应性学习平台的目的是以对学习者的分析、改变呈现方式的策略和领域知识库为依据,为每个学习者制定学习策略。尽管适应性学习系统具有了一些个性化特性,但大都是通过测试学习者掌握所学知识的情况制定学习策略的,这只考虑了部分网络学习的行为,没有考虑学习者的学习习惯、偏好和学习兴趣等网络学习行为属性特征。本文在此基础上引入了数据挖掘技术,提出了基于数据挖掘的个性化学习系统模型。
2.基于数据挖掘的个性化学习系统
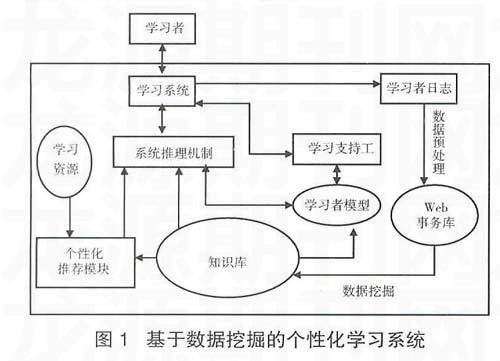
基于数据挖掘的个性化学习系统在适应性学习系统基础上加入了数据挖掘处理和个性化推荐模块,如图1所示。[2]在此引入数据挖掘的技术,使得学习系统能够根据学生的学习行为特征,考虑学习者的学习习惯、学习偏好和学习兴趣等,而不是仅仅考虑知识水平的进程,从而可以更好地提供个性化学习服务。[3]
在基于数据挖掘的个性化学习系统中,数据挖掘的主要数据来源是学习者访问学习网站时在服务器端留下的记录信息。这些数据作为学习者日志将在经过预处理后,形成具体的Web事务库,通过具体的Web挖掘算法来进行模式发现。如基于FLaAT的加权偏爱模式的挖掘算法,构成知识库,利用知识库对学习者实施个性化推荐学习。[4]
三、基于数据挖掘的个性化学习推荐模块
个性化的学习应该是一个学习者访问学习站点时享受的个性化服务。[5][6]如果学习者无需注册信息,那么在学习系统的个性化推荐模块中就将学习者归结为一类,然后根据该类学习者的访问规律进行Web页面的推荐。随着学习者的访问推进,挖掘算法会将学习者归结到不同的学习者类中,因为不同的学习者类有不同的个性,所以可以通过不断地对学习者的当前访问进行个性化分析,给学习者提供个性化的服务。
1.基于数据挖掘的个性化学习推荐
进行Web站点个性化推荐的工具就是Web访问信息挖掘,即利用数据挖掘的思想和方法,对Web服务器上学习者的访问日志进行Web访问信息挖掘,挖掘出学习者的访问规律。
Web站点个性化推荐的主要步骤为:
(1)模型化页面和学习者;
(2)对页面和学习者进行分类;
(3)在页面和对象之间进行匹配;
(4)判断当前访问的类别以进行推荐。[7][8]
学习者对Web站点的访问存在某种有序关系,这种有序关系反映的是学习者的特性,可以代表该学习者的兴趣,也就是说群体学习者自身的特性和访问序列有很强的相关性。这种有序关系表现在两个方面:(1)当前学习者的访问序列是一种有序序列;(2)曾经访问过站点的学习者的访问也是一种有序序列。因此需要一种挖掘方法把这种有序关系所代表的学习者特性关系挖掘出来。所以进行聚类挖掘的目的就是从学习者的访问日志中识别出与当前学习者相似的那一些学习者,根据这些学习者的访问特性以对当前学习者提供推荐。基于聚类方法的个性化方法的主要步骤为:
(1)将学习者访问事务的顺序关系特性挖掘出来;
(2)对这种顺序关系进行路径聚类;
(3)在每个聚类集中挖掘出被访问页面之间的相互关系,得到个性化分析;
(4)识别当前学习者的访问序列;
(5)针对当前学习者的个性化分析而进行个性化推荐。
2.个性化推荐模块
该模块主要分为离线部分和在线部分,如图2所示。
(1)离线部分
离线部分的工作由数据准备和特定的访问挖掘任务组成。数据准备将Web服务器的学习者访问日志文件以及站点的相关文件生成学习者事务文件;利用学习者加权偏爱浏览路径的挖掘算法和基于模糊相似关系的聚类算法生成学习者访问偏爱路径、学习者聚类和学习页面聚类。[3]通过个性化推荐为在线部分的学习者动态地推荐下一步访问操作。
(2)在线部分
在线部分的工作是利用离线部分生成学习者访问偏爱路径、学习者聚类和学习页面聚类等个性化推荐内容,再根据学习者当前的访问操作,动态地推荐下一步访问操作。
个性化推荐内容的产生建立在学习者上一次会话的基础上,随着学习者学习行为特征的变化会得到不同的推荐内容,从而体现出个性化的本质。
四、个性化学习系统的数据挖掘处理模块
将数据预处理的结果存储到学习者会话数据库中,然后对其进行挖掘:
(1)统计分析:学习者访问网页的时间会被记录,因此可以通过相邻两次访问网页的时间差来大致计算学习者访问某页面停留的时间,由此计算出学习者学习某项内容所花的时间,这在一定程度上可以反映学习者对这一课程或这一内容的感兴趣程度。
(2)关联规则:利用关联规则可以发现学习者之间的有趣联系或相关联系,然后将它们之间的超链接动态提供给学习者,使学习者的网络学习更为方便。例如,访问A学习资源的学习者中有多大比例同时也访问了B学习资源,如果该比例超过给定值,就可以认为该关联规则是有趣的,下一次有学习者访问A学习资源时,就可以将B学习资源推荐给该学习者。如我们发现学习《数据结构》的学习者大都会浏览《离散数学》、《C程序设计》的网页,就可以在《数据结构》的网页下面动态产生《离散数学》、《C程序设计》的超链接,或者把它们结合在一起推荐给学习者。
(3)聚类分析:将一组物理的抽象对象,根据它们之间的相似程度分为若干组,其中相似的对象构成一组。个性化网络学习中主要有页面聚类和学习者聚类。如果通过聚类发现某些网页属于同一网页聚类,当学习者访问其中一页时,就可以推荐类中其他页面。学习者聚类中的学习者具有相似的学习行为,可以对他们提供相同的个性化服务。如当我们发现大多数计算机大一学生学习《离散数学》,就可以把这门课程推荐给所有的计算机一年级学生。聚类算法主要有划分算法、层次算法、基于密度的算法、基于网格的算法、基于距离的算法、基于等价关系的算法等。
(4)序列模式:发现学习者在一定的持续时间内的访问序列。如当发现有一定比例的学生学习课程1后一段时间又学习了课程2,那么当发现某学习者学习课程1时,就可以在一段时间后向该学习者推荐课程2。序列模式的挖掘可以采用关联规则中的Apriori算法变种,也可以采用基于数据投影的序列模式增长算法。
(5)频繁访问组:发现学习者频繁访问的路径。如当发现学习者频繁访问以下网页序列(A, B, C, D, E),那么就可以将D、E网页作为推荐链接直接放在A网页中,这样学习者就可以更为方便地访问到该页面了。
五、结束语
数据挖掘技术在网络学习系统中的应用提高了学习系统的个性化服务水平,为系统的决策分析提供了辅助手段。使学习系统能够根据学习者的知识结构、学习行为等个性特征进行个性化教学,以提高学习者学习的积极性和主动性,增强学习者的内部动机,提高学习效率。同时有利于改善教育网站的设计及建立个性化的教育网站。但由于认知领域的复杂性和个体的差异性,学习过程中的太多偶然因素使得实现真正个性化的学习,还面临着许多值得探讨的问题。
参考文献:
[1]陈肖生.网络教育与学习适应性研究综述[J].中国远程教育,2002(3).
[2]杨威,史春秀,巩进生.信息技术教学导论[M].北京:电子工业出版社,2003.3.
[3]邓辉.论网络环境下的学生特征分析系统设计[J].开放教育研究,2003(1).
[4]吴瑞.模糊和粗糙环境下的网络用户浏览模式研究[C].天津大学论文,2006.
[5]舒蓓,申瑞民,王加俊.个性化的远程学习模型[J].计算机工程与应用,2001(9):90-96.
[6]邓辉.网络个性化学习学生特征分析系统的分析与设计[J].远程教育杂志,2003(1):11-13.
[7]李国.基于Web日志挖掘远程教育系统的研究[C].山东师范大学,2006.
[8]金花.一种新的Web日志挖掘算法的研究[C].大连交通大学.2005.6.
(编辑:杨馥红)